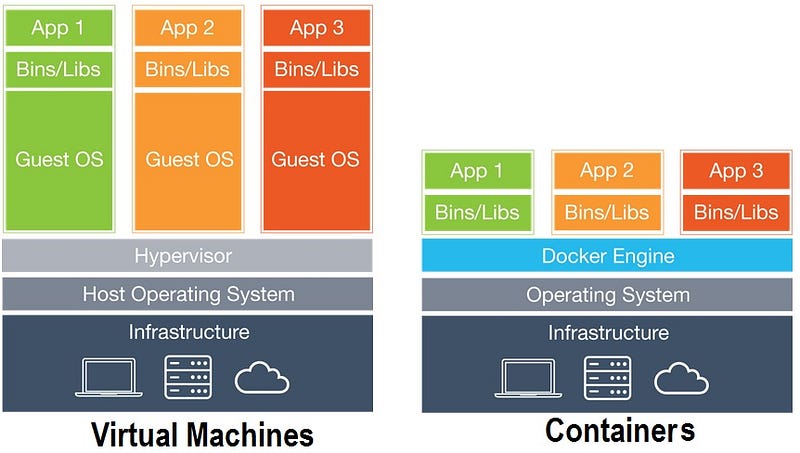
Microservices are going all over the enterprise. It changed the way people write software within enterprise eco system. The advantages of containerized deployments and CI/CD processes and cloud-native application architectures provided the base platform for wider microservices adoption. When it comes to enterprise software, Java has been the first choice for decades and still it is the case. Writing a microservice in Java is pretty simple and straightforward. You can just write a JAX-RS application and run that within a web container like tomcat or use an embedded server like jetty. Even though you can write a simple micro service like that, when deploying this microservice within a production system, it needs lot more capabilities. Some of them are
Monitoring
Performance
Error handling
Extensibility
In this article, I will be guiding the user through a 5 step tutorial on how to implement Java microservices with WSO2 MSF4J.
Create your first microservice
If you have Java and Maven installed in your computer, creating your first microservice is as easy as just entering the below mentioned command in a terminal.
mvn archetype:generate -DarchetypeGroupId=org.wso2.msf4j -DarchetypeArtifactId=msf4j-microservice -DarchetypeVersion=1.0.0 -DgroupId=org.example -DartifactId=stockquote -Dversion=0.1-SNAPSHOT -Dpackage=org.example.service -DserviceClass=HelloService
Once you execute the above command, it will create a directory called “stockquote” and within that directory, you will find the artifacts related to your first microservice.
With the above command, we specify the package name as “org.example.service” and the service class as “HelloService”. Within the src directory, you can find the package hierachy and the source file with the name “HelloService.java”. In addition to this source file, there is another source file with the name “Application.java” which will be used to run the microservice in the pre-built service runtime.
After generating the microservice, you can create an IDE project by using either of the below mentioned commands based on the preferred IDE.
mvn idea:idea (for Intellij Idea)
mvn eclipse:eclipse (for eclipse)
Once this is done, you can open the generated source files using the preferred IDE. Let’s have a look at the source files.
HelloService.java
@Path("/service") public class HelloService {
@GET @Path("/") public String get() { // TODO: Implementation for HTTP GET request System.out.println("GET invoked"); return "Hello from WSO2 MSF4J"; } // more code lines here |
This is the main service implementation class which will execute the business logic and have the microservice related configurations through annotations which are a sub set of JAX-RS annotations.
@Path - This annotation is used to specify the base path of the API as well as resource level path (We have “/service” as the base path and “/” as the resource path)
@GET - This is the http method attached to a given method (for get() method)
In the above class, change the base path context from “/service” to “/stockquote” by changing the “@Path” annotation at the class level.
@Path("/stockquote") public class HelloService { |
In addition to this class, there is another class generated with the command which is “Application.java”.
Application.java
public class Application { public static void main(String[] args) { new MicroservicesRunner() .deploy(new HelloService()) .start(); } } |
This class is used to run the microservice within the msf4j runtime. Here we create an instance of the “MicroservicesRunner” class with an object of the “HelloService” class which we have implemented our microservice logic and then initiating the object with “start” method call.
We are all set to run our first microservice. Go inside the stockquote directory and execute the following maven command to build the microservice.
mvn clean install
After the command completion, you will see that there is a jar file generated at the target/ directory with the name “stockquote-0.1-SNAPSHOT.jar”. This is your “fat” jar which contains the “HelloService” as well as msf4j run time. Now you can run the microservice with the following command.
java -jar target/stockquote-0.1-SNAPSHOT.jar
If all goes well, you will see the following log lines in the console which will confirm that your microservice is up and running.
2017-12-15 15:17:03 INFO MicroservicesRegistry:76 - Added microservice: org.example.service.HelloService@531d72ca
2017-12-15 15:17:03 INFO NettyListener:56 - Starting Netty Http Transport Listener
2017-12-15 15:17:04 INFO NettyListener:80 - Netty Listener starting on port 8080
2017-12-15 15:17:04 INFO MicroservicesRunner:122 - Microservices server started in 180ms
Now it is time to send a request and see whether this service actually doing what it is supposed to do (which is echoing back the message “Hello from WSO2 MSF4J”). Open another terminal and run the curl command mentioned below
curl -v http://localhost:8080/stockquote
You will get the following result once the command is executed
Hello from WSO2 MSF4J
Add GET/POST methods to your microservice
Let’s create a microservice which produces something useful. Let’s expand the generated HelloService class to provide stock details based on the user input. We can rename the HelloService class as “StockQuoteService” and implement the methods for “GET” and “POST” operations.
StockQuoteService.java
@Path("/stockquote") public class StockQuoteService {
private Map<String, Stock> quotes = new HashMap<>();
public StockQuoteService() { quotes.put("IBM", new Stock("IBM", "IBM Inc.", 90.87, 89.77)); }
@GET @Path("/{symbol}") @Produces("application/json") public Response get(@PathParam("symbol") String symbol) { Stock stock = quotes.get(symbol); return stock == null ? Response.status(Response.Status.NOT_FOUND).entity("{\"result\":\"Symbol not found = "+ symbol + "\"}").build() : Response.status(Response.Status.OK).entity(stock).build(); }
@POST @Consumes("application/json") public Response addStock(Stock stock) { if(quotes.get(stock.getSymbol()) != null) { return Response.status(Response.Status.CONFLICT).build(); } quotes.put(stock.getSymbol(), stock); return Response.status(Response.Status.OK). entity("{\"result\":\"Updated the stock with symbol = "+ stock.getSymbol() + "\"}").build(); } |
Here, we have used a new annotation “@Produces” to specify the response message content type as “application/json”. Also, the get method is returning a “Response” object which is something native to the msf4j runtime. Also we have used “@PathParam” annotation to access the path parameter variable we have defined within the “@Path” annotation.
In this class, we have used a new class “Stock” which holds the information about a particular stock symbol. The source code for this class can be found in github location mentioned at the end of the tutorial.
Let’s go inside the source directory “step2-get-post/stockquote” and execute the following maven command.
mvn clean install
Now the microservice flat-jar file is created in the target directory. Let’s run it using the following command.
java -jar target/stockquote-0.1-SNAPSHOT.jar
Now the microservice is up and running on default 8080 port. Let’s execute the “GET” and “POST” methods with the following commands.
{"symbol":"IBM","name":"IBM Inc.","high":90.87,"low":89.77}
{"result":"Updated the stock with symbol = GOOG"}
Add interceptors to your microservice
Now we have written a useful microservice with msf4j and it is working as expected. Interceptors is a component which can be used to intercept all the messages coming into a particular microservice. Interceptor will access the message prior to the microservice logic execution. It can be used for purposes like
authentication
throttling
rate limiting
and the interceptor logic can be implemented as a separate component from the business logic of the microservice. It can also be shared across multiple microservices with the model supported by msf4j.
Let’s see how to implement an interceptor logic.
RequestLoggerInterceptor.java
public class RequestLoggerInterceptor implements RequestInterceptor {
private static final Logger log = LoggerFactory.getLogger(RequestLoggerInterceptor.class);
@Override public boolean interceptRequest(Request request, Response response) throws Exception { log.info("Logging HTTP request { HTTPMethod: {}, URI: {} }", request.getHttpMethod(), request.getUri()); String propertyName = "SampleProperty"; String property = "WSO2-2017"; request.setProperty(propertyName, property); log.info("Property {} with value {} set to request", propertyName, property); return true; } } |
The above class has implemented the “RequestInterceptor” interface which is coming from msf4j runtime. It is used to intercept requests coming into a microservice. Within this class, it has overriden the “interceptRequest” method which will execute once the request is received. Interceptor logic will be written here.
Similarly, response can be intercepted by using the “ResponseLoggerInterceptor” which implements the “ResponseInterceptor” interface of the msf4j runtime.
Once the interceptor logic is implemented, we need to engage this interceptor with the microservice using the annotations.
StockQuoteService.java
@Path("/stockquote") public class StockQuoteService {
private Map<String, Stock> quotes = new HashMap<>();
public StockQuoteService() { quotes.put("IBM", new Stock("IBM", "IBM Inc.", 90.87, 89.77)); }
@GET @Path("/{symbol}") @Produces("application/json") @RequestInterceptor(RequestLoggerInterceptor.class) @ResponseInterceptor(ResponseLoggerInterceptor.class) public Response get(@PathParam("symbol") String symbol) { Stock stock = quotes.get(symbol); return stock == null ? Response.status(Response.Status.NOT_FOUND).build() : Response.status(Response.Status.OK).entity(stock).build(); } |
In this main microservice class, we have used the “@RequestInterceptor” and “@ResponseInterceptor” annotations to bind the interceptor classes which has the implementation logic.
Let’s go inside the source directory “step3-interceptor/stockquote” and execute the following maven command.
mvn clean install
Now the microservice flat-jar file is created in the target directory. Let’s run it using the following command.
java -jar target/stockquote-0.1-SNAPSHOT.jar
Now the microservice is up and running on default 8080 port. Let’s execute the “GET” and method with the following commands.
{"symbol":"IBM","name":"IBM Inc.","high":90.87,"low":89.77}
At the terminal window which has the microservice started, you will see the below log entries which are printed from the interceptors which was written.
2017-12-18 12:08:01 INFO RequestLoggerInterceptor:19 - Logging HTTP request { HTTPMethod: GET, URI: /stockquote/IBM }
2017-12-18 12:08:01 INFO RequestLoggerInterceptor:23 - Property SampleProperty with value WSO2-2017 set to request
2017-12-18 12:08:01 INFO ResponseLoggerInterceptor:18 - Logging HTTP response
2017-12-18 12:08:01 INFO ResponseLoggerInterceptor:21 - Value of property SampleProperty is WSO2-2017
Add custom erros with ExceptionMapper
One of the major requirements when writing microservices is the ability to handle errors and provide customized errors. This can be achieved by using the ExceptionMapper concept of the msf4j.
ExceptionMapper has 2 parts.
Exception type
Exception Mapper
First, user has to define the Exception type as a Java Exception.
public class SymbolNotFoundException extends Exception { public SymbolNotFoundException() { super(); }
public SymbolNotFoundException(String message) { super(message); }
public SymbolNotFoundException(String message, Throwable cause) { super(message, cause); }
public SymbolNotFoundException(Throwable cause) { super(cause); }
protected SymbolNotFoundException(String message, Throwable cause, boolean enableSuppression, boolean writableStackTrace) { super(message, cause, enableSuppression, writableStackTrace); } } |
Then the ExceptionMapper can be used to map this exception to a given customized error message.
public class SymbolNotFoundMapper implements ExceptionMapper<SymbolNotFoundException> {
public Response toResponse(SymbolNotFoundException ex) { return Response.status(404). entity(ex.getMessage() + " [from SymbolNotFoundMapper]"). type("text/plain"). build(); } } |
The “SymbolNotFoundMapper” has implemented the “ExceptionMapper” class and within that, we specify the generic type of the “SymbolNotFoundException” which maps to this exception mapper. Inside the “toResponse” method, the customized response generation can be done.
Now, let’s see how this exception mapper is binded to the main microservice. In the “StockQuoteService” class, within the method which binds to the relevant HTTP method, specific exception needs to be thrown as mentioned below.
StockQuoteService.java
@Path("/stockquote") public class StockQuoteService {
private Map<String, Stock> quotes = new HashMap<>();
public StockQuoteService() { quotes.put("IBM", new Stock("IBM", "IBM Inc.", 90.87, 89.77)); }
@GET @Path("/{symbol}") @Produces("application/json") @Timed public Response get(@PathParam("symbol") String symbol) throws SymbolNotFoundException { Stock stock = quotes.get(symbol); if (stock == null) { throw new SymbolNotFoundException("Symbol "+ symbol + " not found"); } return Response.status(Response.Status.OK).entity(stock).build(); } |
In the above implementation, “get” method is throwing “SymbolNotFoundException” which is mapped to the “SymbolNotFoundMapper” which we have mentioned above. When there is an error occur within this method, it will respond back with the customized error.
Let’s go inside the source directory “step4-exception-mapper/stockquote” and execute the following maven command.
mvn clean install
Now the microservice flat-jar file is created in the target directory. Let’s run it using the following command.
java -jar target/stockquote-0.1-SNAPSHOT.jar
Now the microservice is up and running on default 8080 port. Let’s execute the “GET” and method with the following commands.
Symbol WSO2 not found [from SymbolNotFoundMapper]
Monitor your microservice with WSO2 Data Analytics Server (WSO2 DAS)
Now with microservices are implemented with error handling and interceptors, it is essential to monitor these services. WSO2 MSF4J comes with a built in set of annotations to monitor the microservices. These monitoring data can be published into
Details about the monitoring annotations can be found at the following link.
StockQuoteService.java
@Path("/stockquote") public class StockQuoteService {
private Map<String, Stock> quotes = new HashMap<>();
public StockQuoteService() { quotes.put("IBM", new Stock("IBM", "IBM Inc.", 90.87, 89.77)); }
@GET @Path("/{symbol}") @Produces("application/json") @Timed @HTTPMonitored(tracing = true) public Response get(@PathParam("symbol") String symbol) { Stock stock = quotes.get(symbol); return stock == null ? Response.status(Response.Status.NOT_FOUND).build() : Response.status(Response.Status.OK).entity(stock).build(); }
@POST @Consumes("application/json") @Metered @HTTPMonitored(tracing = true) public Response addStock(Stock stock) { if(quotes.get(stock.getSymbol()) != null) { return Response.status(Response.Status.CONFLICT).build(); } quotes.put(stock.getSymbol(), stock); return Response.status(Response.Status.OK). entity("http://localhost:8080/stockquote/"+ stock.getSymbol()).build(); } |
Here, we have used “@Metered” and “@Timed” annotations for measuring the metrics for respective HTTP methods. In addition to that “@HTTPMonitored” annotation publishes metrics data to WSO2 Data Analytics Server.
We need to setup the WSO2 DAS to test the HTTP Monitoring dashboard.
Download WSO2 DAS
Download WSO2 DAS and unpack it to some directory. This will be the DAS_HOME directory.
Configure DAS
Run "das-setup/setup.sh" to setup DAS. Note that the DAS Home directory in the above step has to be provided as an input to that script.The setup script will also copy the already built MSF4J HTTP Monitoring Carbon App (CAPP) to DAS.
Start DAS
From DAS_HOME, run, bin/wso2server.sh to start DAS and make sure that it starts properly. You need to start the DAS with following command to avod the SSLCertificate exception occurs due to self-signed certificates.
sh bin/wso2server.sh -Dorg.wso2.ignoreHostnameVerification=true
Execute following Commands
1. curl -v http://localhost:8080/stockquote/IBM
2. curl -v -X POST -H "Content-Type:application/json" -d '{"symbol":"GOOG","name":"Google Inc.", "high":190.23, "low":187.45}' http://localhost:8080/stockquote
If everything works fine, you can observe the metrics information printed at the console similar to below
org.example.service.StockQuoteService.get
count = 4
mean rate = 0.01 calls/second
1-minute rate = 0.00 calls/second
5-minute rate = 0.04 calls/second
15-minute rate = 0.12 calls/second
min = 1.81 milliseconds
max = 85.22 milliseconds
mean = 2.47 milliseconds
stddev = 1.47 milliseconds
median = 2.20 milliseconds
75% <= 3.34 milliseconds
95% <= 3.34 milliseconds
98% <= 3.34 milliseconds
99% <= 3.34 milliseconds
Access the HTTP Monitoring dashboard
Go to http://localhost:9763/monitoring/. If everything works fine, you should see the metrics & information related to your microservices on this dashboard. Please allow a few minutes for the dashboard to be updated because the dashboard update batch task runs every few minutes. Source code for this tutorial can be found at the following github repository.